VCF Operations for Logs (formerly Log Insight) is a powerful tool allowing us to keep, maintain, and explore logs from the VMware Cloud Foundation components, and this is one of the critical components of any virtual infrastructure.
In this short article, we will deploy VCF Operations for Logs and configure vCenter Server, ESXi hosts, and VCF Operations to send logs to the newly deployed appliance.
Recently I needed to update the NVIDIA GPU driver on my ESXi 8.0U3 hosts. Although it looks simple: upload the new driver to the depot, edit the image, and update hosts, I faced an unexpected issue during remediation of the cluster:
Remediation of cluster failed
Remediation failed for Host 'gpu-esxi-01'
gpu-esxi-01 - Failed to remediate host
Remediation failed for Host 'gpu-esxi-01'
Failed to remove Component NVD-AIE-800(580.95.02-1OEM.800.1.0.20613240), files may still be in use.
Keeping in mind that the host is in the maintenance mode and there is no VMs running on it, the only thing using the GPU driver can be a service like Xorg and/or vGPU Manager. In my case the Xorg service wasn’t running, but vGPU Manager was.
Therefore, the workaround in this situation was simple (but I hope there is a better way): 1. Place ESXi host into maintenance mode and make sure – no VMs are running on it; 2. Enable SSH and connect; 3. Stop the vGPU manager service:
[root@gpu-esxi-01:~] /etc/init.d/nvdGpuMgmtDaemon status
daemon_nvdGpuMgmtDaemon is running
[root@gpu-esxi-01:~] /etc/init.d/nvdGpuMgmtDaemon stop
[root@gpu-esxi-01:~] /etc/init.d/nvdGpuMgmtDaemon status
daemon_nvdGpuMgmtDaemon is not running
4. Return to the cluster update section, and remediate only one host (with a stopped vGPU manager). This time there should not be any problems with installing a new driver; 5. After finishing the remediation, reboot the host; 6. Leave the host from the maintenance mode; 7. Repeat tasks for each host.
After rebooting, you will see that the driver is updated and the host is compliant with the new cluster image.
If you’re using a virtual machine with multiple vGPUs and considering using NVIDIA Collective Communications Library (NCCL) to implement multi-GPU communications, you may face an error like this during nccl-test:
Test NCCL failure common.cu:1279 'unhandled cuda error (run with NCCL_DEBUG=INFO for details) / '
.. ollama-cb-01 pid 1598: Test failure common.cu:1100
In the detailed log we can see errors like:
init.cc:491 NCCL WARN Cuda failure 'operation not supported'
...
init.cc:491 NCCL WARN Cuda failure 'operation not supported'
...
Test NCCL failure common.cu:1279 'unhandled cuda error (run with NCCL_DEBUG=INFO for details) / '
...
One common reason for this issue in the VMware environment is the UVM (Unified Memory), which is disabled by default in the virtual machine.
To enable UVM, power off the VM and add advanced parameters, based on the number of vGPUs attached to it:
Thereafter, power on the VM, and NCCL-Test will likely pass.
Keep in mind, enabling this feature will prevent future live vMotions of the VM with the following error:
A required migration feature is not supported on the "Source" host 'esxi-01'.
vGPU migration is not supported on this VM.
Another problem that can prevent passing the NCCL test is broken P2P vGPU communication. For example, you can run p2pBandwidthLatencyTest from the NVIDIA Cuda-samples package. If you have a problem with P2P, you will see something like that in the output:
Device=0 CAN Access Peer Device=1
Device=1 CAN Access Peer Device=0
I faced this issue with the drivers from the AI Enterprise 7.1 package (580.95). The solution in my case was to update ESXi and VM drivers to version 580.105 (AI Enterprise 7.3 package).
Today, AI is everywhere, and everyone wants a VM with a GPU adapter to deploy/test/play with AI/ML. Although it is not a problem to add a PCI device to the VM (whole GPU), sometimes it can be overkill.
For example, running a small model requires only a small amount of GPU memory, while our server is equipped with modern NVIDIA H200, B200, or even B300 GPUs that have a large amount of memory.
And this is where vGPU comes into play. vGPU allows us to divide a GPU into smaller pieces and share it among a number of VMs located on the host.
In this article, we will focus on how to configure ESXi hosts to run VMs with the vGPU support in vSphere 8.0 Update 3.
In the last few months, many changes happened to VMware certifications, and in this short post, I want to cover those changes.
First and foremost: since October 31, legacy certifications are no longer available, which means we cannot schedule VCP-DCV or VCAP-Design exams anymore.
What about the current available certification? As usual, we can get all the information from the VMware certification page.
Nowadays, the certification focuses on two products: primarily on VMware Cloud Foundation and, in addition, on VMware vSphere Foundation.
Three levels of certification are available: Professional, Advanced-Professional, and Expert.
There are three types of professional exams:
Administration – focused on administrating and implementing the product;
Support – focused on troubleshooting;
Architect – focused on designing the solution.
While administration and support are available for VCF and VVF products, the architect exam is available only for the VCF solution stack.
In total, we have five professional-level exams:
VMware Certified Professional – VMware vSphere Foundation Support (2V0-18.25), blueprint;
VMware Certified Professional – VMware Cloud Foundation Support (2V0-15.25), blueprint;
VMware Certified Professional – VMware vSphere Foundation Administrator (2V0-16.25), blueprint;
VMware Certified Professional – VMware Cloud Foundation Administrator (2V0-17.25), blueprint;
VMware Certified Professional – VMware Cloud Foundation Architect (2V0-13.25), blueprint.
If you are using only the vSphere Foundation stack, you can start with 2V0-16.25 and 2V0-18.25. For VCF administrators, the starting point could be the 2V0-17.25 and 2V0-15.25 exams. Next is to take the Architect exam 2V0-13.25; I assume it’s kind of like the VCAP-Design exam.
The next step is four advanced-professional exams:
VMware Certified Advanced Professional – VMware Cloud Foundation 9.0 vSphere Kubernetes Service (3V0-24.25), blueprint;
VMware Certified Advanced Professional – VMware Cloud Foundation 9.0 Automation (3V0-21.25), blueprint;
VMware Certified Advanced Professional – VMware Cloud Foundation 9.0 Operations (3V0-22.25), blueprint;
VMware Certified Advanced Professional – VMware Cloud Foundation 9.0 Storage (3V0-23.25), blueprint.
You can see by the name that each advanced-level exam focused on a specified topic – Kubernetes, Automation, or Operations, and vSphere storage, primarily vSAN.
Each professional and advanced exam costs $250, consists of 60 questions, has a passing score of 300 (as usual), and requires 135 minutes to clear.
The last step is VCDX – VMware Certified Distinguished Expert. – What? Where is the “Design Expert”? Currently, there is limited information available on the internet, aside from this post and the landing page.
Recently I’ve been asked to deploy a “Monster VM” with 8 H200 GPUs aboard. Although everything looks simple, and there weren’t any problems with VMs with small vGPUs, the first thing I faced after running such a large VM was an error:
Error message from esxi-01: The firmware could not allocate 50331648 KB of PCI MMIO. Increase the size of PCI MMIO and try again.
MMIO size should be calculated based on the number and type of passthrough devices attached to the VM.
According to the doc above, each passthrough NVIDIA H100 (or H200) GPU requires 128 GB of MMIO space.
You can obtain more information about calculating the MMIO size in KB 323402. Please refer to the example, which explains how to calculate MMIO size based on the GPU size.
After adjusting MMIO settings, the VM will boot successfully.
In the previous articles, we updated VMware Cloud Foundation Operations and vCenter Server to version 9.0.1, and just to complete the series, I will add one more post about updating vSphere hosts using a single-cluster image.
Although the overall procedure for updating is the same and simple, you may have heard of or even faced a new token-based authentication to download updates from the Broadcom repositories, and in this article, I will cover this moment too.
In the previous article, we updated VMware Cloud Foundation Operations to version 9.0.1 and now it is time to update vCenter Server.
Although the overall procedure for updating is the same and simple, as you may have heard, or even experienced, there is a new token-based authentication to download updates from the Broadcom repositories, and in this article, I will cover this moment too.
With the release of version 9.0.1 (this is a minor update, not a major one like Update 1) of VCF components, it is good to cover the update procedure of the key VCF component – VMware Cloud Foundation Operations.
In this short article we will walk though this process.
According to the release notes for VMware vSphere 8.0U3e, VMware vSphere Hypervisor (ESXi) can now be downloaded free of charge from the Broadcom support portal:
Broadcom makes available the VMware vSphere Hypervisor version 8, an entry-level hypervisor. You can download it free of charge from the Broadcom Support portal.
Next, I use my own (non-corporate) account without any SiteIDs added.
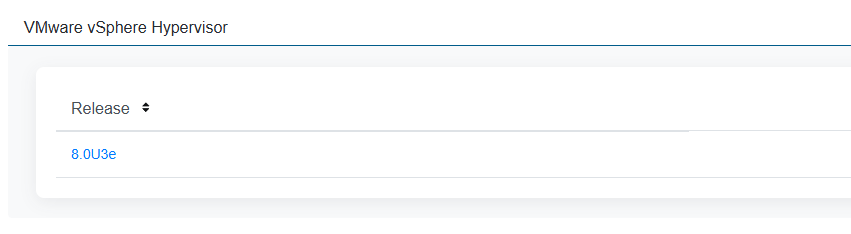
In the Free Downloads section, we can find VMware vSphere Hypervisor:
With the only one release available – 8.0U3e:
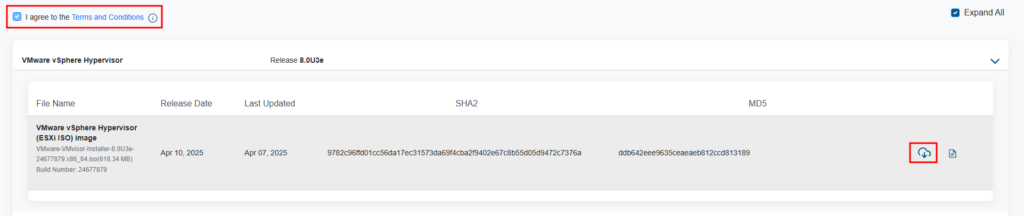
After reading and accepting terms and conditions, we can download the ISO:
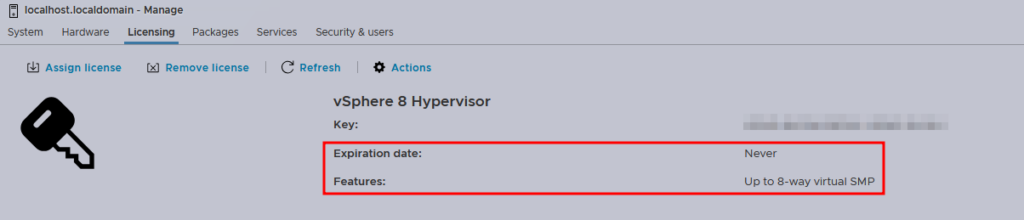
After installing, the first thing we want to see is the license:
We can see that the expiration date is set to never, and the host is limited to 8-way virtual SMP, meaning that you cannot power on the VM that contains more than 8 vCPUs.
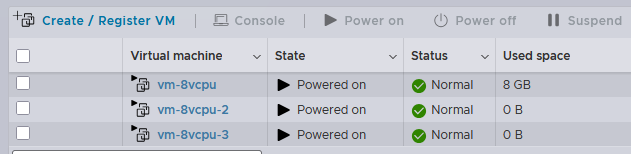
In the example above, you can see that I cannot power on a 16-vCPUs VM. However, I can power three VMs with 8 vCPUs each:
And this is the same way as it worked before. This is a suitable option for extra-small deployments, labs, and testing. For large environments, you should definitely consider purchasing VVF or VCF licenses.
Regarding the license key, you don’t need to get one as it was before. It is already installed in the ISO. According to the screenshots shared on Reddit, all downloads use the same key.